Was this page helpful?
Caution
You're viewing documentation for a previous version. Switch to the latest stable version.
Using the perf utility with Scylla¶
This article contains useful tips & tricks for using the perf utility with Scylla. The perf utility is particularly useful when debugging a pegged shard.
Due to its thread-per-core nature, looking at aggregates is rarely useful as it tends to hide bad behavior that is localized to specific CPUs. Looking at an individual CPU will make those anomalies easier to see. Once you notice that a Scylla shard requires investigation (for example, when the Scylla Monitor shard view shows that a particular shard is more loaded than others), you can use the seastar-cpu-map.sh script described here to determine which Linux CPU hosts that Scylla shard. For example:
.. code-block:: bash
seastar-cpu-map.sh -n scylla -s 0
Output:
In the above example, shard 0 is investigated using the -s argument and providing the shard number. The results show that shard 0 runs on Linux CPU 1. In all perf commands that follow, you can add the -C 1 argument to restrict perf to look only at CPU 1.
When is perf useful?¶
Perf` is most useful when the CPU being probed runs at 100% utilization so that you can identify large chunks of execution time used by particular functions.
Note that due to polling, Scylla will easily drive CPUs to 100% even when it is not bottlenecked. It will spin (poll) for some time, waiting for new requests. It tends to show in the perf reports as functions related to polling having high CPU time.
Perf can also be a useful tool when you suspect that something that shouldn’t be running is running. One example is systems with very high reactor_utilization (indicating non-polling work), where the Linux view of system CPU utilization is also high. It indicates that the Linux Kernel, not Scylla, is the main user of the CPU, so additional investigation is needed.
perf top¶
Perf top shows a point-in-time view of the system. The figure below shows the result of running perf top -C 1.
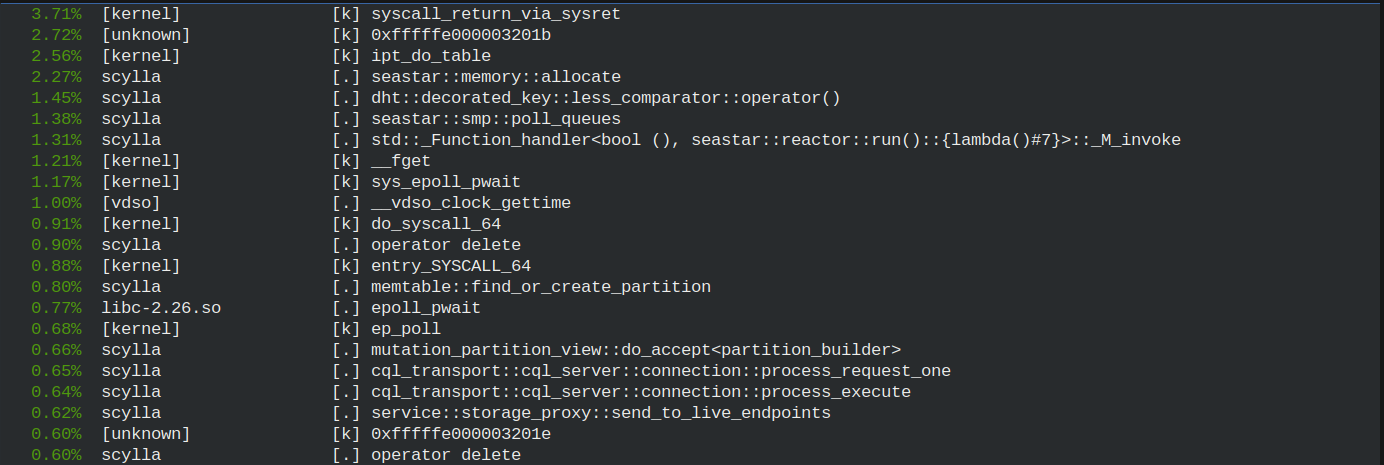
Callgraphs¶
Perf can generate callgraphs. They are useful when you want to understand the complete call chain that results in a function being called. You can add --call-graph=dwarf -F 99 to any recording command, such as perf top or perf record, to generate a callgraph.
For example, to record the callgraphs in CPU2:
sudo perf record -C 2 --call-graph=dwarf -F 99
You can dump the results to the trace.txt file by running:
sudo perf report --no-children --stdio > /tmp/trace.txt